Celebrity twitter followers by gender
The most popular accounts on twitter have millions of followers, but what are their demographics like? Twitter doesn't collect or release this kind of information, and even things like name and location are only voluntarily added to people's profiles. Unlike Google+ and Facebook, twitter has no real name policy, they don't care what you call yourself, because they can still divine out useful information from your account activity.
For example, you can optionally set your location on your twitter profile. Should you choose not to, twitter can still just geolocate your IP. If you use an anonymiser or VPN, they could use the timing of your account activity to infer a timezone. This could then be refined to a city or town using the topics you tweet about and the locations of friends and services you mention most.
I chose to look at one small aspect of demographics: gender, and used a cheap heuristic based on stated first name to estimate the male:female ratios in a sample of followers from these very popular accounts.
Top 100 twitter accounts by followers
A top 100 list is made available by Twitter Counter. It's not clear that they have made this list available through their API, but thanks to the markup, a quick hack is to scrape the usernames using RCurl and some regex:
require("RCurl")
top.100 <- getURL("http://twittercounter.com/pages/100")
# split into lines
top.100 <- unlist(strsplit(top.100, "\n"))
# Get only those lines with an @
top.100 <- top.100[sapply(top.100, grepl, pattern="@")]
# Grep out anchored usernames: <a ...><a href='https://github.com/username' class='user-mention'>@username</a></a>;
top.100 <- gsub(".*>@(.+)<.*", "\\1", top.100)[2:101]
head(top.100)
# [1] "katyperry" "justinbieber" "BarackObama" ...
R package twitteR
Getting data from the twitter API is made simple by the twitteR package. I made use of Dave Tang's worked example for the initial OAuth setup, once that's complete the twitteR package is really easy to use.
The difficulty getting data from the API, as ever, is to do with rate limits. Twitter allows 15 requests for follower information per 15 minute window. (Number of followers can be queried by a much more generous 180 requests per window.) This means that to get a sample of followers for each of the top 100 twitter accounts, it'll take at a minimum 1 hour 40 mins to stay on the right side of the rate limit. I ended up using 90 second sleep windows between requests to be safe, making a total query time of two and a half hours!
Another issue is possibly to do with strange characters being returned and breaking the JSON import. This error crops up a lot and meant that I had to lower the sample size of followers to avoid including these problem accounts. After some highly unscientific tests, I settled on about 1000 followers per account which seemed a good trade-off between maximising sample size but minimising failure rate.
# Try to sample 3000 followers for a user:
username$getFollowers(n=3000)
# Error in twFromJSON(out) :
# Error: Malformed response from server, was not JSON.
# The most likely cause of this error is Twitter returning
# a character which can't be properly parsed by R. Generally
# the only remedy is to wait long enough for the offending
# character to disappear from searches.
Gender inference
Here I used a relatively new R package, rOpenSci's gender (kudos for resisting gendR and the like). This uses U.S. social security data to probabilistically link first names with genders, e.g.:
devtools::install_github("ropensci/gender")
require("gender")
gender("ben")
# name proportion_male proportion_female gender
# 1 ben 0.9962 0.0038 male
So chances are good that I'm male. But the package also returns proportional data based on the frequency of appearances in the SSA database. Naively these can be interpreted as the probability a given name is either male or female. So in terms of converting a list of 1000 first names to genders, there are a few options:
- Threshold: if >.98 male or female, assign gender, else ignore.
- Probabilistically: use random number generation to assign each case, if a name is .95 male and .05 female, on average assign that name to females 5% of the time.
- Bayesian-ish: threshold for almost certain genders (e.g. .99+) and use this as a prior belief of gender ratios when assigning gender to the other followers for a given user. This would probably lower bias when working with heavily skewed accounts.
I went with #2 here. Anecdotal evidence suggests it's reasonably accurate anyway, with twitter analytics (using bag of words, sentiment analysis and all sorts of clever tricks to unearth gender) estimating my account has 83% male followers (!), with probabilistic first name assignment estimating 79% (and that's with a smaller sample). Method #3 may correct this further but the implementation tripped me up.
Results

So boys prefer football (soccer) and girls prefer One Direction, who knew? Interestingly Barack Obama appears to have a more male following (59%), as does Bill Gates with 67%.
At the other end of the spectrum, below One Direction, Simon Cowell is a hit with predominantly female twitter users (70%), as is Kanye West (67%) and Khloe Kardashian (72%).
Another surprise is that Justin Bieber, famed as teen girl heartthrob, actually has a more broad gender appeal with 41 / 59 male-female split.
Interactive charts
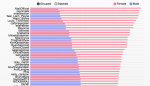
Using the fantastic rCharts library, I've put together some interactive graphics that let you explore the above results further. These use the NVD3 graphing library, as opposed to my previous effort which used dimple.js.
The first of these is ordered by number of followers, and the second by gender split. The eagle-eyed among you will see that one account from the top 100 is missing from all these charts due to the JSON error I discuss above, thankfully it's a boring one (sorry @TwitPic).
Where would your account be on these graphs? Somehow I end up alongside Wayne Rooney in terms of gender diversity :s
Caveats
- A lot of the time genders can't be called from an account's first name. Maybe they haven't given a first name, maybe it's a business account or some pretty unicode symbols, maybe it's a spammy egg account. This means my realised sample size is <<1000, sometimes the majority of usernames had no gender (e.g. @UberSoc, fake followers?).
 This (big) chart includes % for those that couldn't be assigned (NA)
This (big) chart includes % for those that couldn't be assigned (NA) - The SSA data is heavily biased towards Western (esp. US) and non-English names are likely to not be assigned a gender throughout. This is a shame, if you know of a more international gender DB please let me know.
- I'm sampling most recent followers, so maybe accounts like Justin Bieber have a much higher female ratio in earlier followers than those which have only just hit the follow button.
- The sample size of 1000 followers per account is smaller than I'd like, especially for accounts with 50 million followers.

If you have other ideas of what to do with demographics data, or have noticed additional caveats of this study, please let me know in the comments!
Full code to reproduce this analysis is available on Github.
This post was originally published on my
Wordpress blog.