What are the most common RNG seeds used in R scripts on Github?
In the R programming language, the random number generator (RNG) is seeded each session using the current time and process ID. Via the magic of the popular Mersenne Twister PRNG, the values stored in .Random.seed are used sequentially each time "randomness" is invoked in a function. This means, of course, that the same function run in different R sessions can produce varying results, and in the case of modelling a system sensitive to initial conditions the observed differences could be huge.
For this reason it's common to manually set the PRNG seed (using set.seed() in R), thereby creating the same .Random.seed vector which can be drawn from in your analysis to produce reproducible results. The actual value passed to this function is irrelevant for practical purposes — for whatever reason I generally user the same number across projects (42) — so this made me wonder: what values do the major R developers tend to pick?
To Github
The Github API is currently in a transitional period between versions 2 and 3 and has (annoyingly) limited code search results to specific users or organisations. This means to perform a code search programmatically, I'll need a list of R users.
Google BigQuery
One way of building a list is through Github archive. The dev (Ilya Grigorik) has put up a public dataset with Google BigQuery, which is a neat cloud-based platform for querying huge datasets. My SQL isn't all that, but the Google BigQuery interface is really functional (e.g. it autocompletes table fields) and makes it easy to get the data you're looking for.
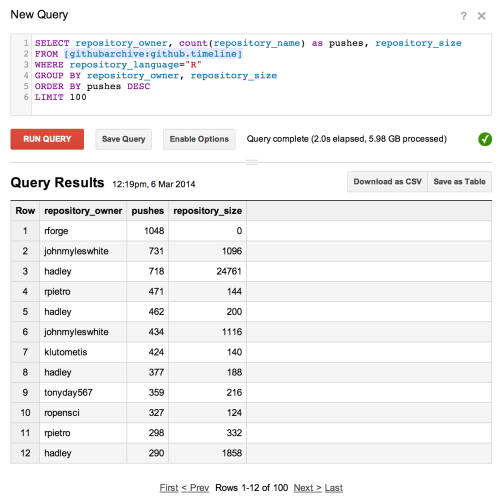
In this case I pulled out R code repositories ordered by repo pushes (as a heuristic for codebase size and activity, I guess) with their owner's username. It was this list of names I then used for the API query.
Github API
It looks like there's a decent set of R bindings for the Github API, but it's not clear how they work with code search, so I opted for the messier option of calling curl through system(). To build the command to search the API per user:
getCMD <- function(user){
cmd <- paste0("curl -H 'Accept: application/vnd.github.v3.text-match+json Authorization: token ",
oauth, "' 'https://api.github.com/search/code?q=set.seed+in:file+language:R+user:",
user,"&page=1&per_page=500' | grep 'fragment' -")
return(cmd)
}
As you can see this is pretty rough and ready, there may be a pagination issue if someone sets PRNG seeds everywhere but it'll do.
You can then run the command and pull out the returned string matches for the query, in this case I searched for "set.seed" and then used Haldey Wickham's stringr R package to regexp out the number (if any) passed to the function.
getPRNGseeds <- function(user){
print(user)
api.result <- system(getCMD(user), intern=T)
if(is.null(attr(api.result, "status"))) {
seeds <- cbind(user,
str_match(api.result, "set\\.seed\\((\\d+)\\)")[,2])
Sys.sleep(10)
return(seeds)
} else {
cat(user, " failed")
return(cbind(user, NA))
}
}
The Github API spits out JSON data (ignored and just grepped out in the above) so I looked into a couple of smarter ways of parsing it. Firstly there's the jsonlite R package which offers the fromJSON() function to import JSON data into what resembles a sometimes-hard-to-work-with nested R object. It seems like the Github API query results return too many nested layers to produce a useful object in this case. Another option is jq, a command-line program which has a neat syntax for dealing specifically with the JSON data structure — I'll definitely be using it for more complex JSON wrangling in the future.
The data
Despite the harsh search limitations I ended up with 27 users who owned the top 100 R repositories, and of those 15 used set.seed() somewhere (or at least something like it). However the regex fails in some cases — where a variable is being passed to the function instead of an integer, for one. Long story short, I scraped together 187 lines of set.seed(\d+) from some of the big names in the R community and here's how the counts looked:

So plain old 1 is the stand-out winner!
There's a few sequences in there (123, 321, 1234, 12345) and some date references (2011, 20051028), but surprisingly few programmer in-jokes or web-culture references, save a lone 1337 and I guess some binary.
1410 (or 1014 in less-sensible countries) and 141079 look like they could be a certain R developer's birthday and birth year, but that's pure speculation :)
Here's one of those awful wordle / wordcloud things too.

Hopefully as the roll-out of the v3 Github API progresses the current search restriction will be lifted, still this was a fun glimpse at other programmer's conventions!
Full code to reproduce in this gist.
This post was originally published on my
Wordpress blog.